𐄷 Weight Standardization#
[How to Use] - [Suggested Hyperparameters] - [Technical Details] - [Attribution]
Computer Vision
Weight Standardization is a reparametrization of convolutional weights such that the input channel and kernel dimensions have zero mean and unit variance. The authors suggested using this method when the per-device batch size is too small to work well with batch normalization models. Additionally, the authors suggest this method enables using other normalization layers instead of batch normalizaiton while maintaining similar performance. We have been unable to verify either of these claims on Composer benchmarks. Instead, we have found weight standardization to improve performance with a small throughput degradation when training ResNet architectures on semantic segmentation tasks. There are a few papers that have found weight standardization useful as well.
|
|---|
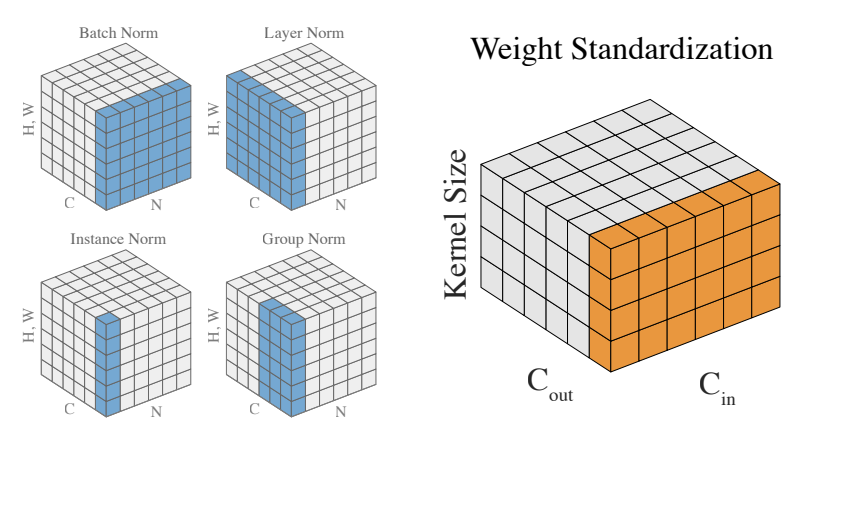
Comparing various normalization layers applied to activations (blue) and weight standardization applied to convolutional weights (orange). This figure is Figure 2 in Qiao et al., 2019. |
How to Use#
Functional Interface#
# Run the Weight Standardization algorithm directly on the model using the Composer functional API
import composer.functional as cf
import torch
import torch.nn.functional as F
def training_loop(model, train_dataloader):
opt = torch.optim.Adam(model.parameters())
# Only set `n_last_layers_ignore` if the classification layer(s) are convolutions
cf.apply_weight_standardization(model, n_last_layers_ignore=0)
loss_fn = F.cross_entropy
model.train()
for epoch in range(1):
for X, y in train_dataloader:
y_hat = model(X)
loss = loss_fn(y_hat, y)
loss.backward()
opt.step()
opt.zero_grad()
break # stop early for testing, remove if copying code
training_loop(my_cnn_model, my_train_dataloader)
Composer Trainer#
# Instantiate the Weight Standardization algorithm and pass it into the Trainer
# The trainer will automatically run it at the appropriate point in the training loop
from composer.algorithms import WeightStandardization
from composer.trainer import Trainer
# Train model
# Only ignore last layers if the classification layer(s) are convolutions
weight_standardization = WeightStandardization(n_last_layers_ignore=0)
trainer = Trainer(
model=cnn_composer_model,
train_dataloader=my_train_dataloader,
eval_dataloader=my_eval_dataloader,
max_duration='1ep',
algorithms=[weight_standardization]
)
trainer.fit()
Implementation Details#
Weight standardization is implemented using PyTorch’s parametrization package to reparametrize convolutional weights to have zero mean and unit standard deviation across the input channel and kernel dimensions. This standardization is computed on each forward pass during training.
The parameter n_last_layers_ignore specifies how many layers at the end of the network to ignore when applying weight standardization. This is essential if the classification layer(s) are convolutional since weight standardization should not be applied to the classification layer(s). Before applying weight standardization, the model is symbolically traced with PyTorch’s torch.fx. The symbolic trace provides the model’s modules in the order they are executed instead of the order they are defined. Depending on the model, the symbolic trace could fail, resulting in a warning and potentially incorrect behavior when using n_last_layers_ignore.
Suggested Hyperparameters#
We found the best performance resulted from setting n_last_layers_ignore equal to the number of classification layers that are convolutional. For example, we set n_last_layers_ignore=0 for training ResNet-50 on ImageNet since the classification is a single linear layer and we set n_last_layers_ignore=15 for training DeepLabv3+ on ADE20k since the DeepLabv3+ classification head consists of 15 convolution layers.
Technical Details#
For ResNet-50 trained on ImageNet, we measured similar accuracy when using weight standardization. For DeepLabv3+ with a ResNet-101 backbone trained on ADE20k, we measured a +0.7 mIoU improvement when using n_last_layers_ignore=15 and training from scratch i.e. without pre-trained weights. In addition to the improvements at the end of training, we observed larger improvements early in training and sometimes a decrease in training loss. This suggests the potential for weight standardized models to be trained with more regularization. We have only tested the performance improvement from this method on ResNet architectures.
🚧 Note
Weight standardization is unlikely to work well when using pre-trained weights if the pre-trained weights were trained without weight standardization.
Attribution#
Micro-Batch Training with Batch-Channel Normalization and Weight Standardization by Siyuan Qiao, Huiyu Wang, Chenxi Liu, Wei Shen, Alan Yuille. arXiv preprint arXiv:1903.10520 (2019).
The Composer implementation of this method and the accompanying documentation were produced by Landan Seguin at MosaicML.