➗ Factorize#
[How to Use] - [Suggested Hyperparameters] - [Technical Details] - [Attribution] - [API Reference]
Computer Vision, Natural Language Processing
Factorize splits a large linear or convolutional layer into two smaller ones that compute a similar function. This can be applied to models for both computer vision and natural language processing.
|
|---|
Figure 1 of Zhang et al. (2015). (a) The weights |
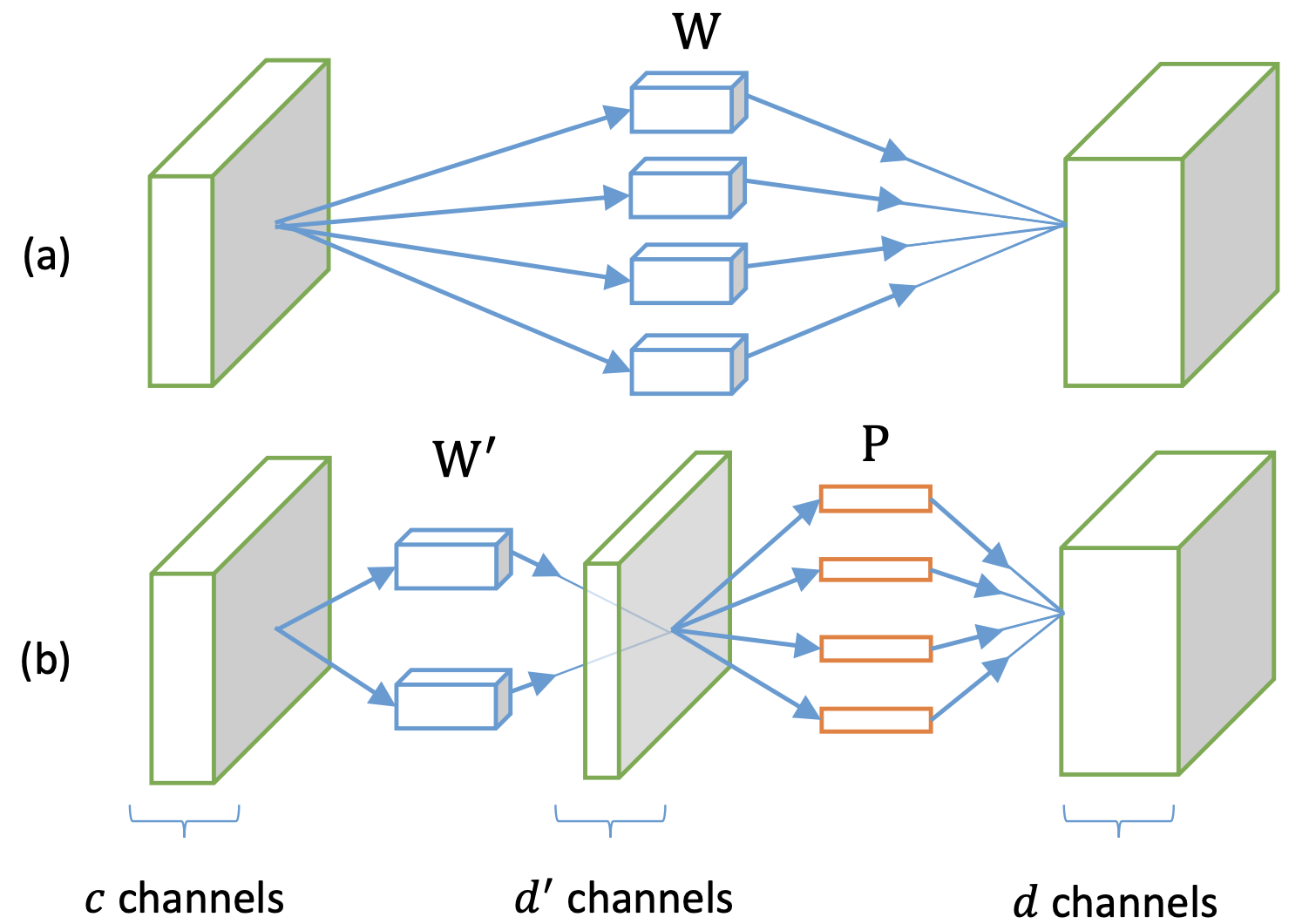
How to Use#
Functional Interface#
# Run the Factorization algorithm directly on the model using the Composer functional API
import torch
import torch.nn.functional as F
import composer.functional as cf
def training_loop(model, train_loader):
opt = torch.optim.Adam(model.parameters())
# only need to pass in opt if apply_factorization is used after optimizer
# creation; otherwise, only the model needs to be passed in.
cf.apply_factorization(
model,
factorize_convs=True,
factorize_linears=True,
min_channels=512,
latent_channels=0.25,
min_features=512,
latent_features=0.25,
optimizers=opt
)
loss_fn = F.cross_entropy
model.train()
for epoch in range(1):
for X, y in train_loader:
y_hat = model(X)
loss = loss_fn(y_hat, y)
loss.backward()
opt.step()
opt.zero_grad()
Composer Trainer#
# Instantiate the algorithm and pass it into the Trainer
# The trainer will automatically run it at the appropriate point in the training loop
from composer.algorithms import Factorize
from composer.trainer import Trainer
factorize = Factorize(
factorize_convs=True,
factorize_linears=True,
min_channels=256,
latent_channels=0.25,
min_features=256,
latent_features=128
)
trainer = Trainer(
model=model,
train_dataloader=train_dataloader,
eval_dataloader=eval_dataloader,
max_duration='10ep',
algorithms=[factorize]
)
trainer.fit()
Suggested Hyperparameters#
For Factorize to have any effect on Linear modules, it is necessary to have factorize_linears=True and min_features small enough that at least one Linear module has at least this many input and output features.
Similarly, for Factorize to have any effect on Conv2d modules, it is necessary to have factorize_convs=True, and min_channels small enough that at least one Conv2d module has at least this many input and output features. This is most likely to be an issue with CIFAR-10 ResNets such as ResNet-20 and ResNet-56, which have at most 64 channels.
While factorizing with latent_{features,channels} < 0.5 always reduces the number of FLOPs needed by a module, factorizing small modules is unlikely to result in a speedup. This is because small operations are limited by memory bandwidth, not computation. Since factorization increases memory bandwidth usage in order to save compute, it is not helpful in this regime.
We suggest setting min_channels >= 512, min_features >= 512, latent_channels <= 0.25, and latent_features <= 0.25 to obtain any speedup.
Technical Details#
Based on ResNet-50 experiments, we have not observed Factorize to ever be helpful.
Even with conservative settings like min_channels=512, latent_channels=128, we observe over a 1% accuracy loss and only a small (<5%) throughput increase.
We have provided this implementation and method card for informational purposes, since factorization is a popular technique in the research literature.
❗ Factorize Did Not Improve Efficiency in Our Experiments
Factorize provided no improvements in (and often decreased) accuracy, and provided very modest throughput increases in our experiments. It is possible that Factorize may still be helpful in other settings.
At present, only factorization before training is supported. This is because of limitations of PyTorch Distributed Data Parallel. We hope to allow factorization during training in the future. This might allow more intelligent allocation of factorization to different layers based on how well they can be approximated. To work around this limitation, one can save the model, stop training, load and alter the model, and then restart training.
Factorize can be applied to any model with linear or convolutional layers but is most likely to be useful for large models with many channels or large hidden layer sizes. However, factorization may not work with your model if it makes special assumptions about linear layers and their attributes. For example, factorization will not work with torch.nn.MultiHeadAttention modules, because MultiHeadAttention expects its linear submodule to have a weight attribute, and FactorizedLinear does not have this attribute.
At present, only factorizing linear and conv2d modules is supported (i.e., factorizing conv1d and conv3d modules is not supported).
❗ Only Linear and 2D Convolution Modules are Supported
Factorization does not currently support other kinds of layers, for example 1D and 3D convolutions.
Attribution#
Factorizing convolution kernels dates back to at least Gotsman 1994. To the best of our knowledge, the first papers to apply factorization to modern neural networks were:
Speeding up convolutional neural networks with low rank expansions by Max Jaderberg, Andrea Vedaldi, and Andrew Zisserman. Published in the British Machine Vision Conference in 2014.
Exploiting Linear Structure Within Convolutional Networks for Efficient Evaluation by Emily Denton, Wojciech Zaremba, Joan Bruna, Yann LeCun, and Rob Fergus. Published in NeurIPS 2014.
Our factorization structure most closely matches that in:
Accelerating Very Deep Convolutional Networks for Classification and Detection by Xiangyu Zhang, Jianhua Zou, Kaiming He, and Jian Sun. Published in IEEE TPAMI in 2016.
The Composer implementation of this method and the accompanying documentation were produced by Davis Blalock at MosaicML.
API Reference#
Algorithm class: composer.algorithms.Factorize
Functional: composer.functional.apply_factorization()