🎨 AugMix#
[How to Use] - [Suggested Hyperparameters] - [Technical Details] - [Attribution] - [API Reference]
Computer Vision
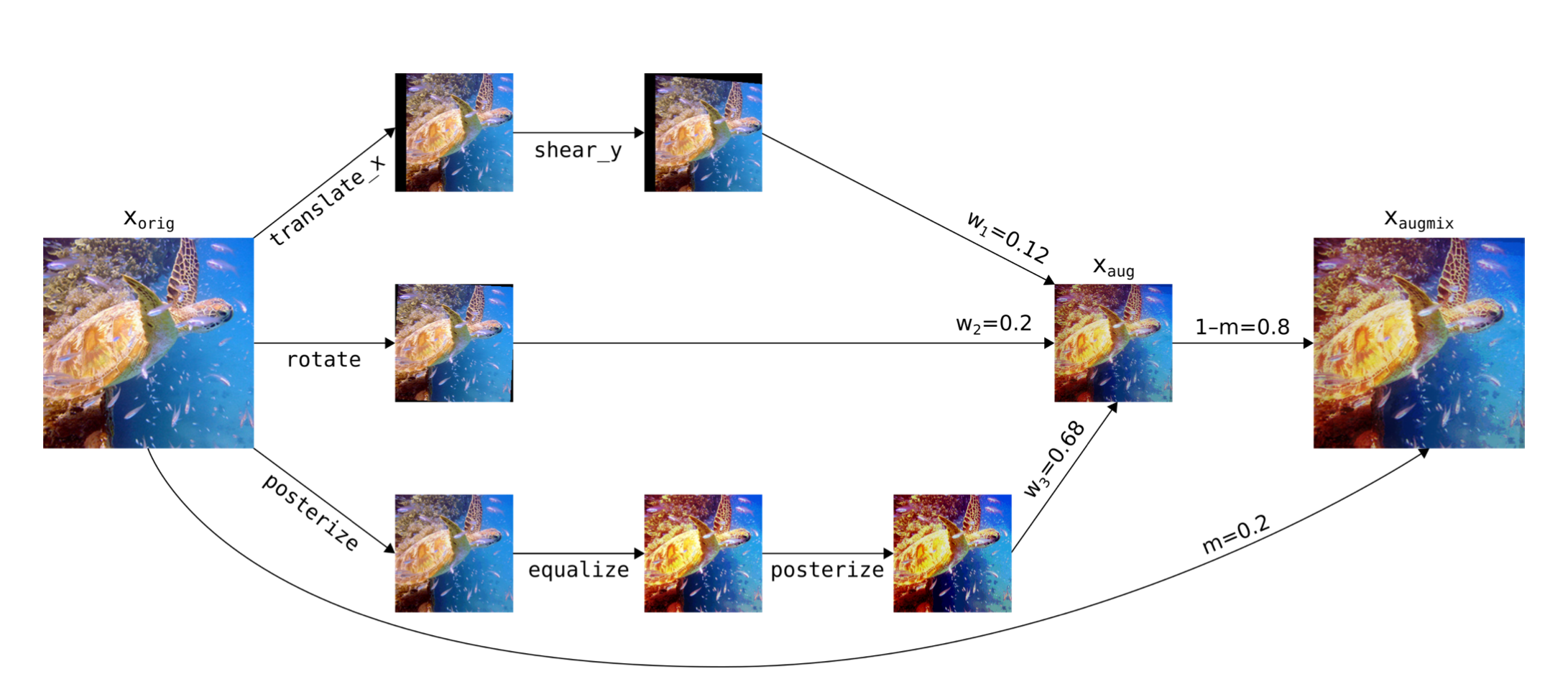
For each data sample, AugMix creates an augmentation chain by sampling depth image augmentations from a set (e.g. translation, shear, contrast).
It then applies these augmentations sequentially with randomly sampled intensity.
This is repeated width times in parallel to create width different augmented images.
The augmented images are then combined via a random convex combination to yield a single augmented image, which is in turn combined via a random convex combination sampled from a Beta(alpha, alpha) distribution with the original image.
Training in this fashion regularizes the network and can improve generalization performance.
|
|---|
An image of a turtle that undergoes three different augmentation chains is pieced together using a convex combination and combined with the original image. Figure 4 from Hendrycks et al. (2020). |
How to Use#
Functional Interface#
# Run augmix on the image to produce a new augmixed image
from typing import Union
import torch
from PIL.Image import Image as PillowImage
import composer.functional as cf
from composer.algorithms.utils import augmentation_sets
def augmix_image(image: Union[PillowImage, torch.Tensor]):
augmixed_image = cf.augmix_image(
img=image,
severity=3,
width=3,
depth=-1,
alpha=1.0,
augmentation_set=augmentation_sets["all"]
)
return augmixed_image
Torchvision Transform#
# Create a callable for AugmentAndMix which can be composed with other image augmentations
import torchvision.transforms as transforms
from torchvision.datasets.vision import VisionDataset
from composer.algorithms.augmix import AugmentAndMixTransform
augmix_transform = AugmentAndMixTransform(severity=3,
width=3,
depth=-1,
alpha=1.0,
augmentation_set="all")
composed = transforms.Compose([augmix_transform, transforms.RandomHorizontalFlip()])
dataset = VisionDataset(data_path, transform=composed)
Composer Trainer#
# Instantiate the algorithm and pass it into the Trainer
# The trainer will automatically run it at the appropriate points in the training loop
from composer.algorithms import AugMix
from composer.trainer import Trainer
augmix_algorithm = AugMix(severity=3,
width=3,
depth=-1,
alpha=1.0,
augmentation_set="all")
trainer = Trainer(
model=model,
train_dataloader=train_dataloader,
eval_dataloader=eval_dataloader,
max_duration="1ep",
algorithms=[augmix_algorithm],
)
trainer.fit()
Implementation Details#
AugMix leverages torchvision.transforms to add a transformation to the dataset which will be applied per image on the CPU. The transformation takes in a PIL.Image and outputs a PIL.Image with AugMix applied.
The functional form of AugMix (augmix_image()) requires AugMix hyperparameters when it is called.
The Torchvision transform form of AugMix (AugmentAndMixTransform) is composable with other dataset transformations via torchvision.transforms.Compose.
The class form of AugMix runs on Event.FIT_START and inserts AugmentAndMixTransform into the set of transforms in a torchvision.datasets.VisionDataset dataset.
Suggested Hyperparameters#
As per Hendrycks et al. (2020), we found that width=3, depth=-1, (depth=-1 means that depth will be randomly sampled from the uniform distribution {1, 2, 3} for each data sample), severity=3 (out of a maximum possible value of 10), and alpha=1 (i.e., performing no mixing with the original image) worked well for different models of the ResNet family. We used augmentation_set=all.
❗ Potential CPU Bottleneck
Further increasing
widthordepthsignificantly decreases throughput when training ResNet-50 on ImageNet due to bottlenecks in performing data augmentation on the CPU.
Technical Details#
AugMix randomly samples depth image augmentations (with replacement) from the set of {translate_x, translate_y, shear_x, shear_y, rotate, solarize, equalize, posterize, autocontrast, color, brightness, contrast, sharpness}.
The augmentations use the PILLOW Image library (specifically Pillow-SIMD); we found that OpenCV-based augmentations result in similar or worse performance.
AugMix is applied after “standard” image transformations, such as resizing and cropping, and before normalization.
Each augmentation is applied with an intensity that is randomly sampled uniformly from [0.1-severity] (severity ≤ 10). where severity is a unit-free upper bound on the intensity of an augmentation and is mapped to the unit specific for each augmentation. For example, severity would be mapped to degrees for the rotation augmentation with severity=10 corresponding to 30°.
Hendrycks et al.’s original implementation of AugMix also includes a custom loss function computed across three samples (an image and two AugMix’d versions of that image). We omit this custom loss function from our AugMix implementation because it effectively triples the number of samples required for a parameter update step, imposing a significant computational burden. Our implementation, which consists only of the augmentation component of AugMix, is referred to by Hendrycks et al. as “AugmentAndMix.”
❗ AugMix Provided Limited Benefits in Our Experiments
We found that using AugMix with the hyperparameters recommended by Hendrycks et al. can increase the data augmentation load on the CPU so much that it bottlenecks training. Depending on the hardware configuration and model, we found that those hyperparameters increase training time by 1.1x-10x.
Hendrycks et al. report a 13.8% accuracy improvement on CIFAR-10C (a benchmark for corruption robustness) over baseline for a 40-2 Wide ResNet and a 1.5-10% improvement over other augmentation schemes. Hendrycks et al. also report a 1.5% improvement over a baseline ResNet-50 on ImageNet, but this result uses AugMix in combination with the aforementioned custom loss function. When omitting the custom loss function and using the AugMix augmentation scheme alone, we observe an accuracy gain of about 0.5% over a baseline ResNet-50 on ImageNet. However, the increased CPU load imposed by AugMix substantially reduces throughput.
AugMix will be more useful in overparameterized regimes (i.e. larger models) and for longer training runs. Larger models typically take longer to run on a deep learning accelerator (e.g., a GPU), meaning there is more headroom to perform work on the CPU before augmentation becomes a bottleneck. In addition, AugMix is a regularization technique, meaning it makes training more difficult. Doing so can allow models to reach higher quality, but this typically requires (1) larger models with more capacity to perform this more difficult learning and (2) longer training runs to allow these models time to learn.
🚧 AugMix May Reduce Quality for Smaller Models and Shorter Training Runs
AugMix is a regularization technique that makes training more difficult for the model. Because AugMix is a regularization technique, it can allow models to reach higher quality for
(1) longer training runs and…
(2) overparameterized models
However, for shorter training runs or smaller models it may reduce quality.
🚧 Composing Regularization Methods
As general rule, composing regularization methods may lead to diminishing returns in quality improvements while increasing the risk of creating a CPU bottleneck.
❗ CIFAR-10C and ImageNet-C are no longer out-of-distribution
CIFAR-10C and ImageNet-C are test sets created to evaluate the ability of models to generalize to images that are corrupted in various ways (i.e., images that are out-of-distribution with respect to the standard CIFAR-10 and ImageNet training sets). These images were corrupted using some of the augmentation techniques in
augmentation_set=all. If you useaugmentation_set=all, these images are therefore no longer out-of-distribution.
Attribution#
AugMix: A Simple Data Processing Method to Improve Robustness and Uncertainty by Dan Hendrycks, Norman Mu, Ekin D. Cubuk, Barret Zoph, Justin Gilmer, and Balaji Lakshminarayanan. Published in ICLR 2020.
The Composer implementation of this method and the accompanying documentation were produced by Matthew Leavitt at MosaicML.
API Reference#
Algorithm class: composer.algorithms.AugMix, composer.algorithms.AugmentAndMixTransform
Functional: composer.functional.augmix_image()