🥸 ALiBi#
[How to Use] - [Suggested Hyperparameters] - [Technical Details] - [Attribution] - [API Reference]
Natural Language Processing
ALiBi (Attention with Linear Biases) dispenses with position embeddings for tokens in transformer-based NLP models, instead encoding position information by biasing the query-key attention scores proportionally to each token pair’s distance. ALiBi yields excellent extrapolation to unseen sequence lengths compared to other position embedding schemes. We leverage this extrapolation capability by training with shorter sequence lengths, which reduces the memory and computation load.
|
|---|
The matrix on the left depicts the attention score for each key-query token pair. The matrix on the right depicts the distance between each query-key token pair. m is a head-specific scalar that is fixed during training. Figure from Press et al., 2021. |
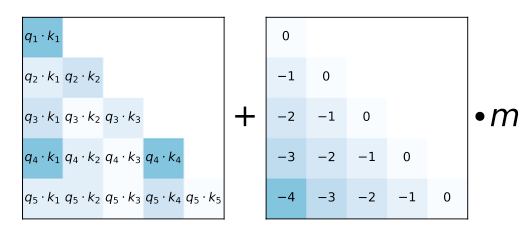
How to Use#
Functional Interface#
# Run the ALiBi algorithm directly on the model using the Composer functional API
import torch
import composer.functional as cf
def training_loop(model, train_loader):
cf.apply_alibi(
model=model,
max_sequence_length=1024,
)
opt = torch.optim.Adam(model.parameters())
loss_fn = F.cross_entropy
model.train()
for epoch in range(num_epochs):
for X, y in train_loader:
y_hat = model(X)
loss = loss_fn(y_hat, y)
loss.backward()
opt.step()
opt.zero_grad()
Composer Trainer#
# Instantiate the algorithm and pass it into the Trainer
# The trainer will automatically run it at the appropriate points in the training loop
from composer.algorithms import Alibi
from composer.trainer import Trainer
alibi = Alibi(
max_sequence_length=1024,
train_sequence_length_scaling=0.25,
)
trainer = Trainer(
model=model,
train_dataloader=train_dataloader,
eval_dataloader=eval_dataloader,
max_duration='1ep',
algorithms=[alibi]
)
trainer.fit()
Implementation Details#
ALiBi is implemented as follows. On Event.INIT:
The model’s position embeddings are expanded to accommodate sequences of up to length
max_sequence_lengthand then “bypassed” by setting them to zero and freezing them.The attribute that computes the self-attention in the model’s self-attention modules is replaced with an ALiBi-enabled self-attention method using graph surgery. Our implementation builds a registry that maps module types to their graph surgery functions. Note: you may need to add to the registry if your model’s self-attention and embedding modules are not included in the registry (see “Supported Models” below).
On
Event.AFTER_DATALOADER, the length of training data sequences in a batch are scaled bytrain_sequence_length_scalingby reshaping the data tensors.
Supported Models#
Our current implementation of ALiBi provides out-of-the-box support for HuggingFace BERT (and RoBERTa) and HuggingFace GPT2 models. This support extends to any models that are superclasses of these models (e.g., the BERT and GPT2 models that can be created using composer.models.create_bert_mlm and composer.models.create_gpt2, respectively, both of which return instances of a composer.models.huggingface.HuggingFaceModel class).
Please be aware that if you use ALiBi with an unsupported model type a logger warning will be generated but no error will be raised. Make sure to check the logs if you are uncertain whether your model is supported by ALiBi.
You can add your own ALiBi implementation by extending the policy_registry that defines the “policy” that maps source module types (e.g., transformers.models.bert.BertSelfAttention) to their respective “replacement functions” (functions that modify instances of the source module or return new modules to replace them). Please see the documentation for composer.algorithms.alibi.attention_surgery_functions.utils.PolicyRegistry for details on the requirements of such implementations and specific examples. The following example demonstrates the basic pattern:
# Example for adding Alibi surgery functions to support a custom transformer model
import torch
import composer.functional as cf
# MyTransformer is the model class. Its modules include instances of EmbeddingLayer and AttentionLayer
from my_custom_models import MyTransformer, EmbeddingLayer, AttentionLayer
# Import the alibi policy registry
from composer.algorithms.alibi.attention_surgery_functions import policy_registry
# Register a surgery function for handling position embeddings in EmbeddingLayer instances
@policy_registry.register(EmbeddingLayer)
def embedding_surgery(module: torch.nn.Module, module_index: int, max_sequence_length: int) -> torch.nn.Module:
# Define code here that augments `module` (an instance of EmbeddingLayer) such that:
# - position embeddings are not used
# - any sequence-sized buffers are rebuilt to support max_sequence_length sized sequences
...
return module # Return the augmented `module`
# Register a surgery function for using Alibi biases to attention in AttentionLayer instances
@policy_registry.register(AttentionLayer)
def attention_surgery(module: torch.nn.Module, module_index: int, max_sequence_length: int) -> torch.nn.Module:
# Define code here that augments `module` (an instance of AttentionLayer) such that:
# - the module has a buffer of Alibi-style attention biases, which are added to the attention logits before applying softmax
# - any sequence-sized buffers are rebuilt to support max_sequence_length sized sequences
...
return module # Return the augmented `module`
# Alibi will now support MyTransformer (and any other model that uses the EmbeddingLayer and AttentionLayer modules)
model = MyTransformer()
cf.apply_alibi(model, max_sequence_length=1024)
Suggested Hyperparameters#
We found that train_sequence_length_scaling=0.25 (sequence length 256) provides appreciable speed and accuracy gains for models evaluated with sequence length 1024.
We observe that performance significantly degrades for ALiBi models trained on sequence lengths ≤128.
As such, we do not recommend training models with sequence lengths ≤256 or train_sequence_length_scaling≤0.03125, whichever is larger.
Technical Details#
ALiBi dispenses with traditional position embeddings and instead adds a static, non-learned bias to the query-key attention scores (or attention weights). This bias is proportional to the distance between the query and key tokens that comprise each attention score. The distances are scaled by m, a head-specific scalar that is fixed during training.
Press et al. found that learning m did not lead to strong extrapolation. They instead set m = (4(log2 H + 3)-1)-h where H is the number of attention heads in a layer and h is the index of the current head.
Press et al. report that models trained with ALiBi maintain similar performance even when tested on sequences 5-10x longer than they were trained on. ALiBi’s extrapolation capabilities can be leveraged to train on shorter sequences. This is desirable because the number of operations required to compute self-attention and the GPU memory usage required to store the resulting representations both increase with the square of the sequence length. In one example scenario, Press et al. reported training to equal perplexity 90% of the time and utilizing 90% of the GPU memory compared to a baseline model with sinusoidal position embeddings. Our experiments show that ALiBi can reduce perplexity by 0.2-0.6, train models 1.15x faster, and utilize 1.2x less GPU memory compared to baseline models (see below).
✅ ALiBi Improves the Tradeoff Between Quality and Training Speed
In our experiments, ALiBi improves the attainable tradeoffs between training speed and the final quality of the trained model. We recommend ALiBi for training language models.
We conducted experiments on the GPT-2 model family trained on OpenWebText on 8x NVIDIA A100-40GBs. We compared baseline models with learned position embeddings and training sequence length 1024 to models using ALiBi with train_sequence_length_scaling=0.25 (i.e., train sequence length 256). We found that train_sequence_length_scaling=0.25 (sequence length 256) provides appreciable speed and accuracy gains for models evaluated at sequence length 1024. Our results are shown in the table below.
Name |
Perplexity |
Δ |
Train Time (s) |
Speedup |
GPU Memory |
Reduction |
|---|---|---|---|---|---|---|
GPT2-52M |
30.78 |
9801 |
92.91% |
|||
GPT2-52M ALiBi 0.25x |
30.54 |
-0.24 |
8411 |
1.16x |
79.79 |
1.16x |
GPT2-83M |
26.57 |
17412 |
97.04 |
|||
GPT2-83M ALiBi 0.25x |
26.19 |
-0.38 |
14733 |
1.18x |
80.97 |
1.20x |
GPT2-125M |
24.11 |
30176 |
95.96 |
|||
GPT2-125M ALiBi 0.25x |
23.49 |
-0.63 |
25280 |
1.19x |
74.83 |
1.28x |
❗ Don’t Set the Sequence Length Too Short
We observed that performance significantly degraded for ALiBi models trained on sequence lengths ≤128, implying that very short sequences (≤128 tokens) may be irreconcilably out-of-distribution with regard to longer sequences. Considering our results together with those of Press et al. leads us to suggest that models with ALiBi should not be trained on sequences ≤256 or
train_sequence_length_scaling≤0.03125, whichever is larger.
Attribution#
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation by Ofir Press, Noah A. Smith, and Mike Lewis. Published in ICLR 2022.
The Composer implementation of this method and the accompanying documentation were produced by Matthew Leavitt and Alex Trott at MosaicML.
API Reference#
Algorithm class: composer.algorithms.Alibi
Functional: composer.functional.apply_alibi()