****(page:launching/run)=
Run Lifecycle#
mcli run -f example.yaml
from mcli import create_run, RunConfig
config = RunConfig(
...
)
run = create_run(run_config)
What happens next?
We manage the submission and orchestration of the runs automatically.
The status of a run (RunStatus object) can be monitored using:
mcli get runs
from mcli import get_run
run = get_run('run')
print(run.status)
run = run.refresh()
print(run.status)
https://console.mosaicml.com
This status represents unique phases the run will enter during its lifecycle:
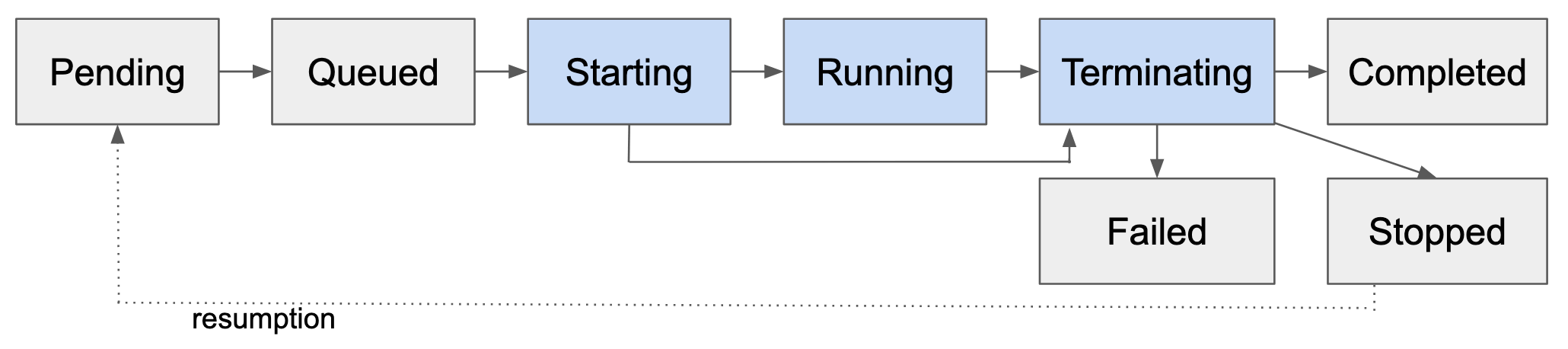
Between the “Starting” and “Terminating” phases, your run will be assigned and consuming node resources on the cluster. For this reason, GPU usage is computed as the difference of:
Start time: The time the run enters the
STARTINGstatusEnd time: The time the run exits the
TERMINATINGstatus
Note that runs will never share GPUs, but could be assigned different GPUs on the same node if the cluster supports it.
Pending (PENDING)#
The run has been submitted but hasn’t been sent to the compute plane or assigned a space in the queue.
Queued (QUEUED)#
The run has been placed in queue to be picked up by the specified cluster.
If there is space on the cluster, the run will likely appear to skip this phase entirely. In other cases, the run may remain in queued for a long time due to the size of the resource request and/or current cluster utilization. You can view active and queued runs on all clusters using:
mcli util
from mcli import get_cluster
cluster = get_cluster("name")
gpus_available = sum(i.gpus_available for i in cluster.utilization.cluster_instance_utils)
print(f"{cluster.name}: "
f"{len(cluster.utilization.active_runs_by_user)} active, "
f"{len(cluster.utilization.queued_runs_by_user)} queued, "
f"{gpus_available} GPUs available")
Starting (STARTING)#
After a run has been scheduled, it goes from the pending to the starting status. In this phase, the scheduler has assigned the run to node(s) in the cluster and has started setting up everything needed to run the workload.
Starting a run includes setting up containers and pulling the docker image you specified when you configured the run. This phase can be time consuming for large images that have not been used recently in the cluster (caching is done with the Always image pull policy in kubernetes).
Running (RUNNING)#
After finishing the setup, the run goes into the Running phase, which is the core phase where the run is executed inside a containers on one or more nodes.
First, any integrations configured for the run are executed, such as cloning a Github repo or installing a pypi package. Integrations are executed in order to produce the required run environment.
Once integrations finish building, the command configured for the run is executed.
During this phase, you can view the stdout and stderr of any commands run using:
mcli logs <run>
from mcli import follow_run_logs
for log in follow_run_logs('run'):
print(log, end='')
https://console.mosaicml.com
Terminating (TERMINATING)#
After exiting the running or starting phase, runs will always enter a “terminating” status. This phase will typically last up to about 30-40 seconds as the orchestration kills any remaining processes and removes the run’s assignment to the node(s). Until this phase is complete, the run can still be consuming resources and other runs cannot be scheduled on these node(s).
From terminating, there are several terminal phases the run may enter into:
Completed: Everything ran smoothly and the run has successfully finished! 🙌Stopped: The run was stopped and is no longer executingFailed: Something went wrong while the run was starting or running
Below are details of each terminal phase
Completed (COMPLETED)#
The run has executed the full command and finished without any errors. You now view the full run logs, examine final run metrics, or saved checkpoints and data.
If you no longer need this run, you can clean it up using:
mcli delete run <run>
from mcli import delete_run
delete_run('run')
https://console.mosaicml.com
Stopped (STOPPED)#
The run started running but did not complete entirely. This state can be entered by stopping the run using:
mcli stop run <run>
from mcli import stop_run
stop_run('run')
https://console.mosaicml.com
A stopped run can then be be restarted using:
mcli run -r <run>
from mcli import start_run
start_run('run')
https://console.mosaicml.com
When a run restarts, it does not automatically save the state of the previous run. Instead, the user code is left responsible for this. If you’re using Composer this is easy to enable through checkpointing and auto-resumption.
On restart, the run will begin the run lifecycle again and execute the series of commands from the very beginning. To see all attempts of a run, you can view the entire lifecycle using:
mcli describe run <run>
from mcli import get_run
run = get_run('run')
print(run.lifecycle)
https://console.mosaicml.com
Failed (FAILED)#
Unfortunately, there are several potential reasons why a run may have failed. This section will go over in depth different failures you may encounter, and how to recover from them.
First, make sure you identify that the run has failed and potentially the reason using:
mcli get run "run"
from mcli import get_run
run = get_run('run')
print(run.status, run.reason)
https://console.mosaicml.com
Below outlines debugging each reason. Take note of the exit code if provided as well
Reason: FailedImagePull#
This means the run failed during the Starting phase when trying to pull the image you’ve specified in the run configuration.
There’s a few reasons this could happen:
The image is private and docker secrets are not configured or does not have access. To fix this, set up docker secrets and confirm you can pull the image with this combination of username and password
The image name is not valid. Double check the image name you entered in the run configuration by describing the run
mcli describe run <run>
from mcli import get_run
run = get_run('run')
print(run.image)
Reason: Error#
This is the catch-all run failure that means something failed when the run was being executed. You’ll want to look at the run logs to debug:
mcli logs <run>
from mcli import get_run_logs
for log in get_run_logs('run', failed=True):
print(log)
The --failed flag will default to showing the logs of the first failed node rank.
Note that since runs execute in a unique process for each nodes, the logs for each rank could be different (e.g. one node could have raised an exit code, which would have triggered all other nodes to fail).
You can manually specify which node rank to view the logs of using the rank flag:
mcli logs <run> --rank 2
from mcli import get_run_logs
for log in get_run_logs('run', rank=2):
print(log, end='')