⚖️ Scale Schedule#
[How to Use] - [Suggested Hyperparameters] - [Technical Details] - [Attribution] - [API Reference]
Scale Schedule changes the number of training steps by a dilation factor and dilating learning rate changes accordingly. Doing so varies the training budget, making it possible to explore tradeoffs between cost (measured in time or money) and the quality of the final model.
|
|---|
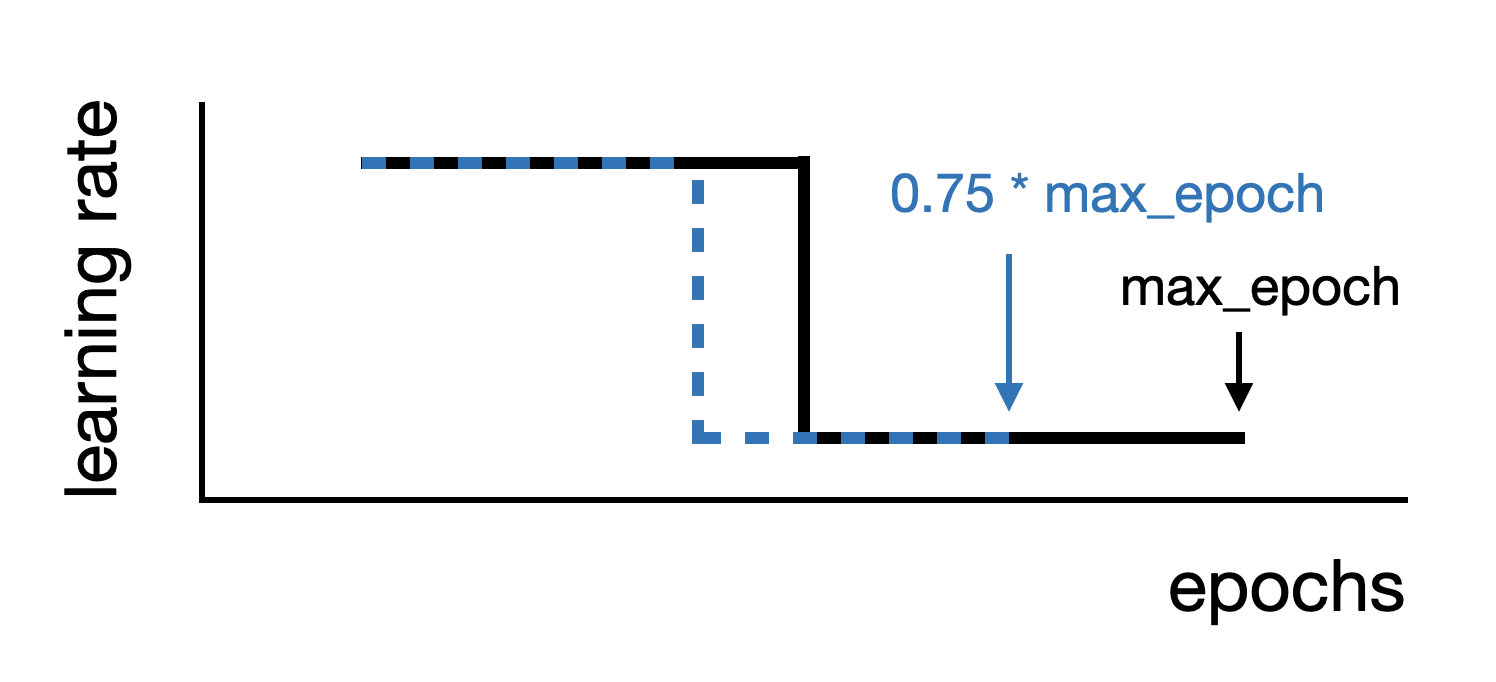
Scale schedule scales the learning rate decay schedule. |
How to Use#
Implementation Details#
Scale schedule is implemented as part of the Trainer via the scale_schedule_ratio argument.
The trainer will scale the max_duration by the scale_schedule_ratio, and also adjust non-warmup milestones
for the learning rate schedulers.
Scale schedule supports all Composer Schedulers:
Decays the learning rate discretely at fixed intervals. |
|
Decays the learning rate discretely at fixed milestones. |
|
Decays the learning rate discretely at fixed milestones, with an initial warmup. |
|
Maintains a fixed learning rate. |
|
Adjusts the learning rate linearly. |
|
Adjusts the learning rate linearly, with an initial warmup. |
|
Decays the learning rate exponentially. |
|
Decays the learning rate according to the decreasing part of a cosine curve. |
|
Decays the learning rate according to the decreasing part of a cosine curve, with an initial warmup. |
|
Cyclically decays the learning rate according to the decreasing part of a cosine curve. |
|
Sets the learning rate to be proportional to a power of the fraction of training time left. |
|
Decays the learning rate according to a power of the fraction of training time left, with an initial warmup. |
See also
The Scheduling Guide more information about Composer Schedulers.
Scale schedule also supports the following PyTorch Schedulers:
For example, the code below will scale the training time by half (to 10 epochs) and also scale the learning rate schedule.
from composer import Trainer
from composer.optim.scheduler import MultiStepScheduler
trainer = Trainer(
...,
max_duration="20ep",
schedulers=MultiStepScheduler(milestones=["10ep", "16ep"]),
scale_schedule_ratio=0.5,
)
# or equivalently, with default SSR=1.0:
trainer = Trainer(
...,
max_duration="10ep",
schedulers=MultiStepScheduler(milestones=["5ep", "8ep"])
)
For additional details on using the scale schedule ratio, see the Scale Schedule Ratio section in the schedulers guide.
Suggested Hyperparameters#
The default scale schedule ratio is 1.0. For a standard maximum number of epochs (these will differ depending on the task), scaling down the learning rate schedule will lead to a monotonic decrease in accuracy. Increasing the scale schedule ratio will often improve the accuracy up to a plateau, although this leads to longer training time and added cost.
Techical Details#
Changing the length of training will affect the final accuracy of the model. For example, training ResNet-50 on
ImageNet for the standard schedule in the composer library leads to final validation accuracy of 76.6%, while
using scale schedule with a ratio of 0.5 leads to final validation accuracy of 75.6%. Training for longer can lead
to diminishing returns or even overfitting and worse validation accuracy. In general, the cost of training is
proportional to the length of training when using scale schedule (assuming all other techniques, such as progressive
resizing, have their schedules scaled accordingly).
Note
The warmup periods of schedulers are not scaled by the scale schedule ratio.
🚧 As general rule, scale schedule can be applied in conjunction with any method. If other methods also perform actions according to a schedule, it is important to modify their schedules to coincide with the altered number of epochs.
Attribution#
The number of training steps to perform is an important hyperparameter to tune when developing a model. This technique appears implicitly throughout the deep learning literature. One example of a systematic study of this approach is the scan-SGD technique in How Important is Importance Sampling for Deep Budgeted Training by Eric Arazo, Diego Ortega, Paul Albert, Noel O’Connor, and Kevin McGuinness. Posted to OpenReview in 2020.
API Reference#
Trainer attribute: scale_schedule_ratio in composer.Trainer