📺 Channels Last#
[How to Use] - [Suggested Hyperparameters] - [Technical Details] - [Attribution] - [API Reference]
Computer Vision, Math Equivalent
Channels Last improves the throughput of convolution operations in networks for computer vision by changing the memory format of activation and weight tensors to contain channels as their last dimension (i.e., NHWC format) rather than the default format in which the height and width are the last dimensions (i.e., NCHW format). NVIDIA GPUs natively perform convolution operations in NHWC format, so storing the tensors this way eliminates transpositions that would otherwise need to take place, increasing throughput. This is a systems-level method that does not change the math or outcome of training in any way.
|
|---|
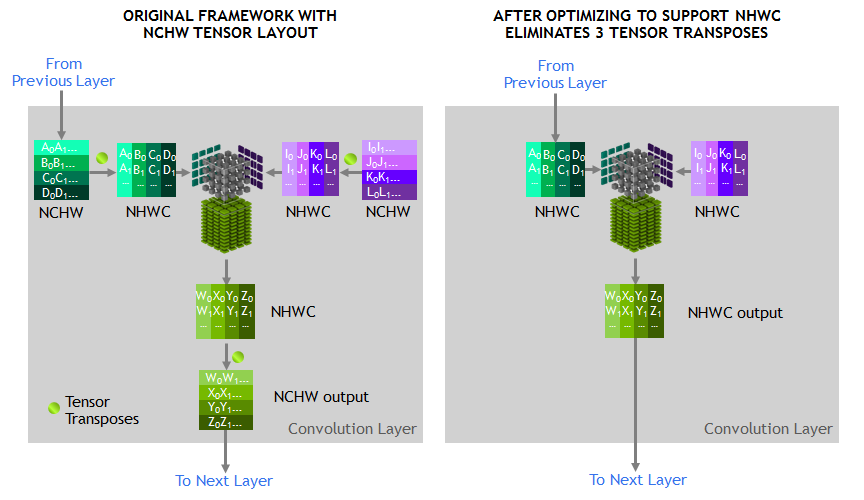
A diagram of a convolutional layer using the standard NCHW tensor memory layout (left) and the NHWC tensor memory layout (right). Fewer operations take place in NHWC format because the convolution operation is natively performed in NHWC format (right); in contrast, the NCHW tensor must be transposed to NHWC before the convolution and transposed back to NCHW after (right). This digram is from NVIDIA. |
How to Use#
Functional Interface#
# Run the Channels Last algorithm directly on the model using the Composer functional API
import composer.functional as cf
def training_loop(model, train_loader):
cf.apply_channels_last(model)
opt = torch.optim.Adam(model.parameters())
loss_fn = F.cross_entropy
model.train()
for epoch in range(num_epochs):
for X, y in train_loader:
y_hat = model(X)
loss = loss_fn(y_hat, y)
loss.backward()
opt.step()
opt.zero_grad()
Composer Trainer#
# Instantiate the algorithm and pass it into the Trainer
# The trainer will automatically run it at the appropriate points in the training loop
from composer.algorithms import ChannelsLast
from composer.trainer import Trainer
channels_last = ChannelsLast()
trainer = Trainer(
model=model,
train_dataloader=train_dataloader,
eval_dataloader=eval_dataloader,
max_duration='1ep',
algorithms=[channels_last]
)
trainer.fit()
Implementation Details#
Channels Last is implemented by converting the entire model to the channels last memory format at the beginning of training using model.to(memory_format=torch.channels_last).
Suggested Hyperparameters#
Channels Last does not have any hyperparameters.
Technical Details#
At a high level, NVIDIA tensor cores require tensors to be in NHWC format in order to get the best performance, but PyTorch creates tensors in NCHW format.
Every time a convolution operation is called by a layer like torch.nn.Conv2D, the cuDNN library performs a transpose operation to convert the tensor into NHWC format. This transpose introduces overhead.
If the model weights are instead initialized in NHWC format, PyTorch will automatically convert the first input activation tensor to NHWC to match, and it will persist the memory format across all subsequent activations and gradients. This means that convolution operations no longer need to perform transposes, speeding up training.
We currently implement this method by casting the user’s model to channels-last format (no changes to the dataloader are necessary). When the first convolution operation receives its input activation, it will automatically convert it to NHWC format, after which the memory format will persist for the remainder of the network (or until it reaches a layer that cannot support having channels last).
✅ Channels Last Improves Training Speed
In our experiments, Channels Last improves the attainable tradeoffs between training speed and the final quality of the trained model. We recommend Channels Last for training convolutional networks.
❗ Overhead from Operations Incompatible with Channels Last Memory Format
If a model has layers that cannot support the channels last memory format, there will be overhead due to PyTorch switching activation tensors back and forth between NCHW and NHWC memory formats. We believe this problem currently affects placing channels last on UNet.
Attribution#
The Composer implementation of this method and the accompanying documentation were produced by Abhi Venigalla at MosaicML.
API Reference#
Algorithm class: composer.algorithms.ChannelsLast
Functional: composer.functional.apply_channels_last()