Elastic Determinism#
Deterministic and reproducible training across varying numbers of GPUs is essential for resizing workloads, debugging distributed training jobs, and more. Streaming is built to provide elastically deterministic training and resumption. For example, a training run on 24 GPUs can be stopped, resumed on 16 GPUs, and later, finished on 48 GPUs, all with the same loss curve and global batch size. Here’s an example of completely deterministic loss curves as the number of GPUs increases from 8 to 64:
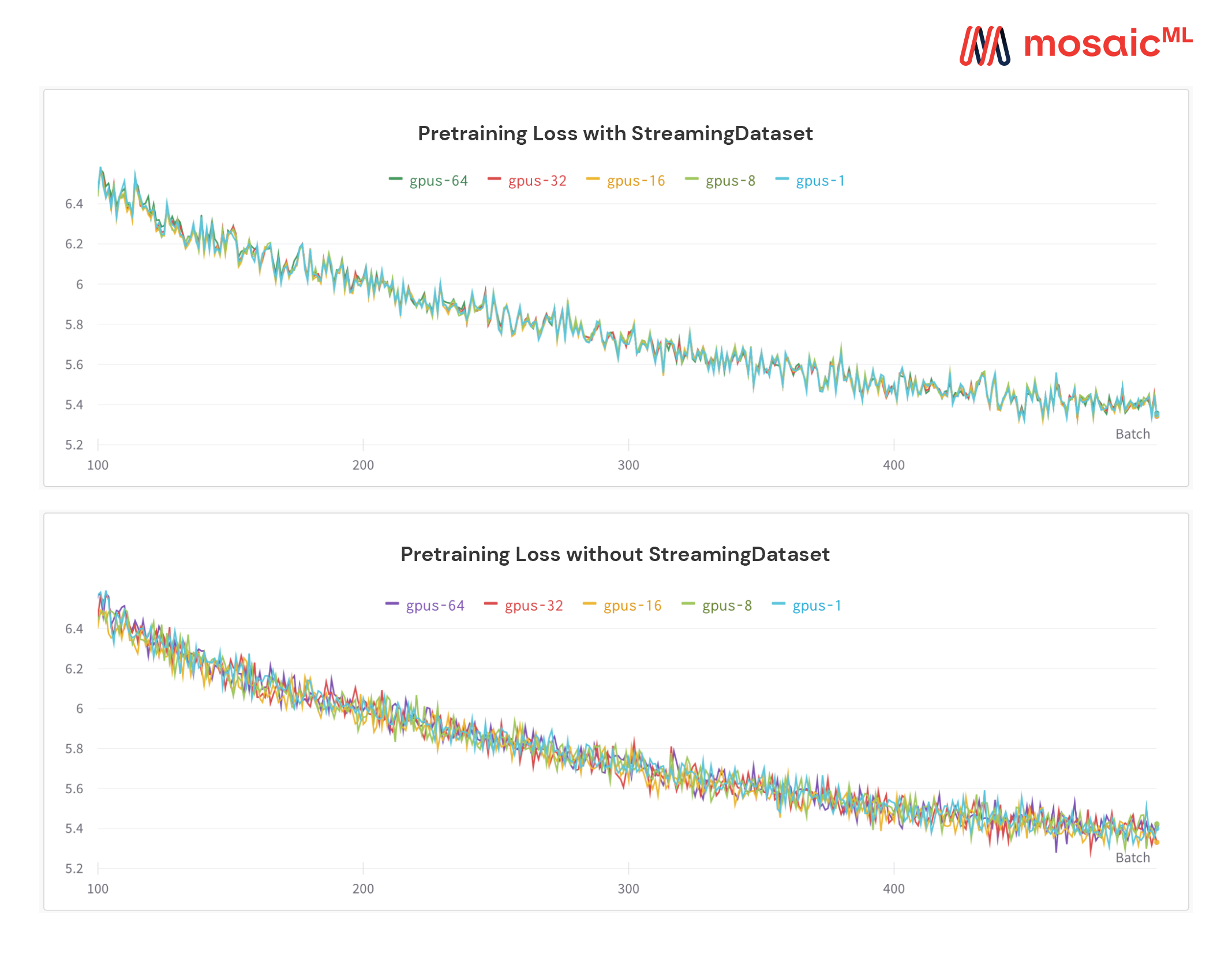
When combining elastic determinism with elastically sharded checkpoints, as our Composer training library does, distributed training becomes easier and much more flexible. See here for more information on Composer’s checkpointing.
Requirements#
For elastic determinism, Streaming merely requires that your global batch size stays constant over the course of the training job, and is also divisible by all the numbers of GPUs you wish to run on. For example, with a global batch size of 18, you can train deterministically on 1, 2, 3, 6, 9, or 18 GPUs, but not on 7, since 18 samples cannot be evenly split among GPUs.
Streaming uses the num_canonical_nodes parameter, which controls the number of buckets into which samples are partitioned, to ensure that the global sample order remains elastically deterministic. To retain determinism between runs, set num_canonical_nodes to the same value. The num_canonical_nodes defaults to the number of physical nodes of the first run.
For example, if Run 1 was trained on 32 GPUs, where each physical node had 8 GPUs, then the total number of physical nodes is 4, and num_canonical_nodes defaults to 4. If Run 2 is required to have the same loss curve as Run 1, explicitly set num_canonical_nodes to 4, and remember to set batch_size accordingly:
# Dataset for Run 1 does not specify `num_canonical_nodes`. Assuming that each physical node has 8 GPUs,
# and Run 1 is launched on 32 GPUs, `num_canonical_nodes` is set to the number of physical nodes, 4.
run_1_32_gpu_dataset = StreamingDataset(
remote = 'oci://some_remote_path/dataset',
local = 'tmp/local/cache',
batch_size = 4, # This is the per-device batch size. Global batch size is 32 gpus * 4 samples/gpu = 128 samples
)
# To make Run 2 have the same loss curve as Run 1, explicitly set `num_canonical_nodes` to 4.
# Assuming Run 2 is launched on 8 GPUs, the `batch_size` (per-device) must increase by a factor of 4
# so that the global batch size stays the same (128 samples).
run_2_8_gpu_dataset = StreamingDataset(
remote = 'oci://some_remote_path/dataset',
local = 'tmp/local/cache',
num_canonical_nodes = 4, # Explicitly set to the same as Run 1 for deterministic training
batch_size = 16, # This is the per-device batch size. Global batch size is 8 gpus * 16 samples/gpu = 128 samples
)
See this section for more information on how num_canonical_nodes is used.